・識別学習された局所方位輪郭特徴量によりパーツ連結性を評価した人体姿勢推定
This paper proposes contour-based features for articulated pose estimation. in single images. Most of recent methods, including general object recognition using graphical models, are designed using tree-structured models with appearance evaluation only within the region of each part. While these models allow us to speed up global optimization in localizing the whole parts, useful appearance cues between neighboring parts are missing. Our work focuses on how to evaluate parts connectivity using contour cues (Fig. 1). Unlike previous works, we locally evaluate parts connectivity only along the orientation between neighboring parts within where they overlap. This adaptive localization of the features is required for suppressing bad effects due to nuisance edges such as those of background clutter and clothing textures, as well as for reducing computational cost. Discriminative training of the contour features improves estimation accuracy more. Experimental results with a public dataset of people images verify the effectiveness of our contour-based features (Fig. 2).
本研究では,複雑背景下で撮影された一枚の静止画像中から人体の姿勢を推定する手法を提案する.この問題では,画像中の各ウィンドウにおける人体の各パーツ(頭,胴,腕など) らしさ,すなわちウィンドウの見えとパーツの見えの類似度を正しく評価することが重要となる.ほとんどの従来手法では,濃度勾配ベースの特徴量のみを用いて各パーツの類似度を計算するため,個人差に依存しにくい類似度評価のために重要な人体輪郭だけでなく,服表面のテクスチャや複雑な背景模様も検出されてしまう問題があった.本研究ではこの問題を解決するために,パーツ類似度評価のための2 段階の処理を新たに提案する.まず第1 に,人体のパーツ領域をより正しく抽出するためのパーツ・背景領域分割法を提案する.この方法では各パーツの候補領域において,各パーツ形状の事前知識を参照したパーツ領域と背景領域を2値化をすることによって,人体輪郭だけを領域特徴量として抽出し,この領域特徴量に基づいて各パーツとの類似度を評価する.第2に,領域特徴量と従来の濃度勾配ベースの特徴量とを統合することにより,両特徴量を相補的に利用したパーツ類似度の評価法を提案する.実験の例を図3に示す.
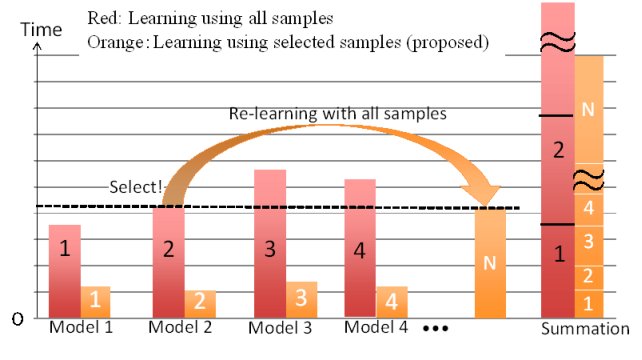
認識のためのモデル学習では,サンプルが多いほど認識性能は向上するが,学習の計算コストはサンプル数に応じて増大してしまう.そこで,学習サンプルを適切に選択し,推定正答率を大きく落とすことのない学習の高速化を提案する.本研究では,人体姿勢推定を研究対象とする.提案法は,一般的な認識問題に適用可能なフレームワークに加え,人体姿勢特徴量に特化した低次元化による高速化も備える点で,従来の手法と異なる.本稿では,サンプルの選択法を3つ提案する.一つはクラスタリングによる選択で,重複的な学習を避ける方法である.二つめは識別境界からの距離による選択で,識別境界の効率的な更新に着目した手法である.三つめは,前述の2つの手法を組み合わせ,時間のかかるクラスタリングと誤検出探索において,人体姿勢推定問題に特化した特徴量の低次元化と枝刈りを加えた.これらの手法について実験を行い,実験の結果,統計的なパラメータに基づいた人体姿勢推定の正答率の低下を3%以下に抑えたまま学習時間を79%削減できた.
提案手法による高速学習で適切なモデルを選択し,そのモデルを全サンプルで
学習することによって,全体の学習時間の大幅削減と従来とおりの高認識率を両立できる(図4).
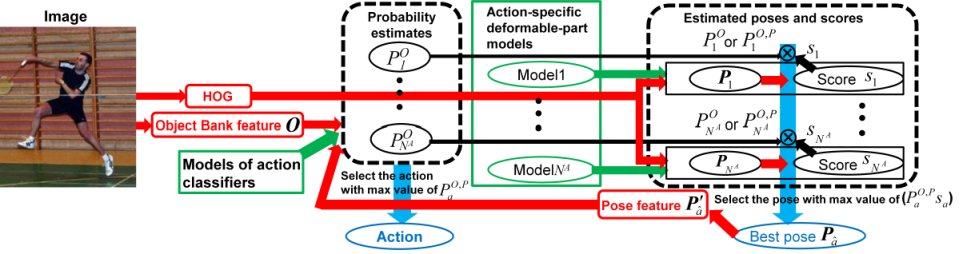
This work proposes an iterative scheme between human action
classification and pose estimation in still images
(Fig. 5). For initial action classification, we
employ global image features that represent a scene (e.g. people,
background, and other objects), which can be extracted without any
difficult human-region segmentation such as pose estimation. This
classification gives us the probability estimates of possible actions
in a query image. The probability estimates are used to evaluate the
results of pose estimation using action-specific models. The
estimated pose is then merged with the global features for action
re-classification. This iterative scheme can mutually improve action
classification and pose estimation, as illustrated in
Fig. 6. Experimental results with a public
dataset demonstrate the effectiveness of global features for
initialization, action-specific models for pose estimation, and action
classification with global and pose features.
This work proposes a method for human pose estimation in still
images. The proposed method achieves self-occlusion-aware
appearance modeling.
Appearance modeling with less accurate appearance data is
problematic because it adversely affects the entire training
process.
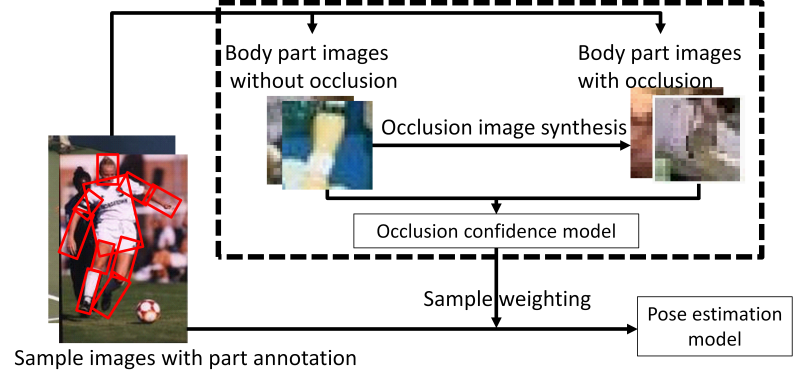
The proposed method evaluates the effectiveness of mitigating the
influence of occluded body parts in training sample images. In order
to improve occlusion evaluation by a discriminatively-trained model,
occlusion images are synthesized and employed with non-occlusion
images for discriminative modeling. The score of this discriminative
model is used for weighting each sample in the training process
(図7).
Experimental results demonstrate that our approach improves the
performance of human pose estimation in contrast to base models.
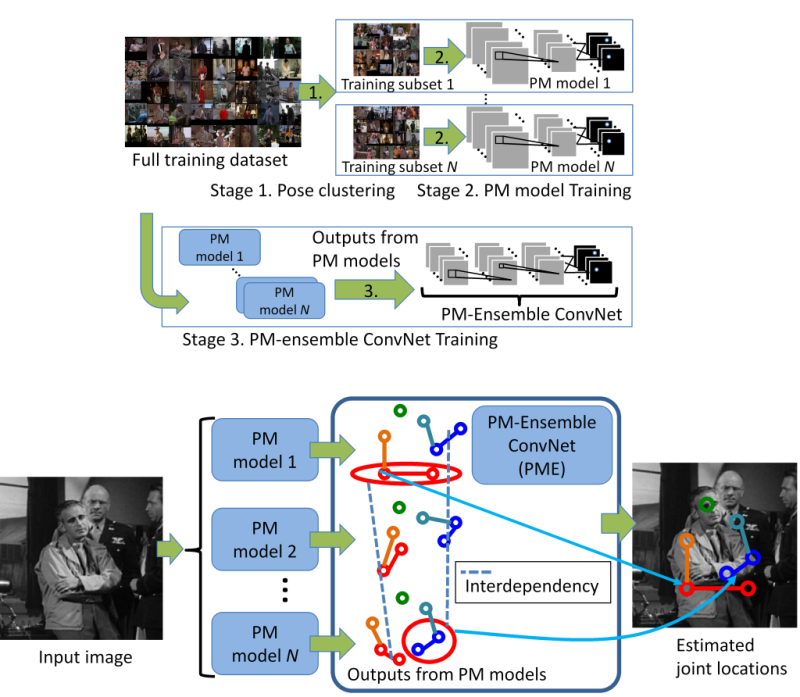
Human pose estimation is a challenging task due to significant appearance variations.
An ensemble of models, each of which is optimized for a limited variety of poses, is capable of modeling a large variety of human body configurations.
However, ensembling models is not a straightforward task
due to the complex interdependence among noisy and ambiguous pose estimation predictions acquired by each model.
We propose to capture this complex interdependence using a convolutional neural network.
Our network achieves this interdependence representation using a combination of deep convolution and deconvolution layers for robust and accurate pose estimation
(図8).
We evaluate the proposed ensemble model on publicly available datasets and show that our model compares favorably against baseline models and state-of-the-art methods.
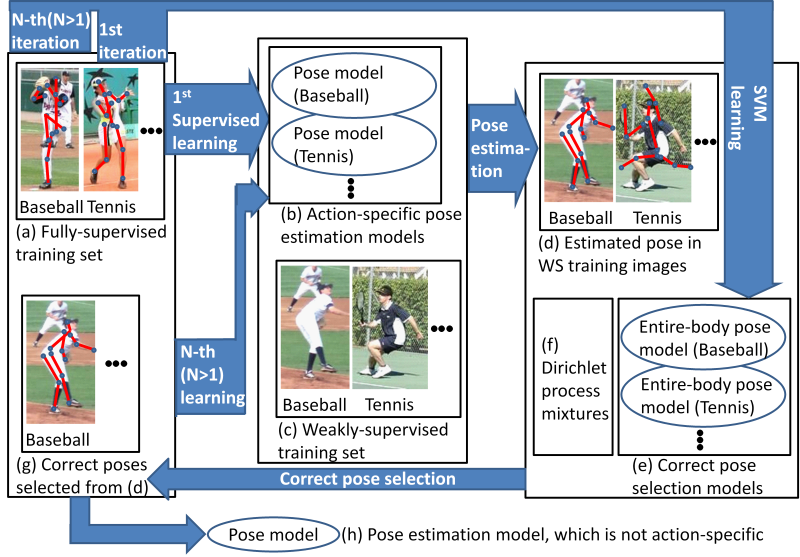
For human pose estimation in still images, this paper proposes three
semi- and weakly-supervised learning schemes. While recent advances
of convolutional neural networks improve human pose estimation using
supervised training data, our focus is to explore the semi- and
weakly-supervised schemes. Our proposed schemes initially learn
conventional model(s) for pose estimation from a small amount of
standard training images with human pose annotations. For the first
semi-supervised learning scheme, this conventional pose model detects
candidate poses in training images with no human annotation. From
these candidate poses, only true-positives are selected by a
classifier using a pose feature representing the configuration of all
body parts. The accuracies of these candidate pose estimation and
true-positive pose selection are improved by action labels provided to
these images in our second and third learning schemes, which are semi-
and weakly-supervised learning. While the first and second learning
schemes select only poses that are similar to those in the supervised
training data, the third scheme selects more true-positive poses that
are significantly different from any supervised poses
(図9). This pose selection is achieved by pose
clustering using outlier pose detection with Dirichlet process
mixtures and the Bayes factor. The proposed schemes are validated
with large-scale human pose datasets.

画像下の数字は,推定に成功した人体パーツの割合を示す.
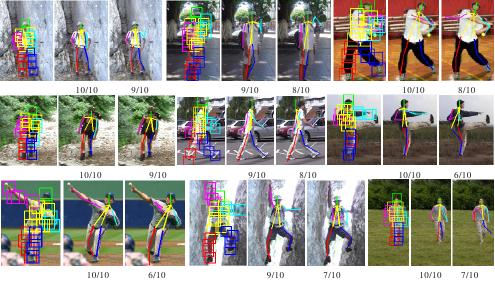
画像下の数字は,推定に成功した人体パーツの割合を示す.