Future-guided offline imitation learning for long action sequences via video interpolation and future-trajectory prediction
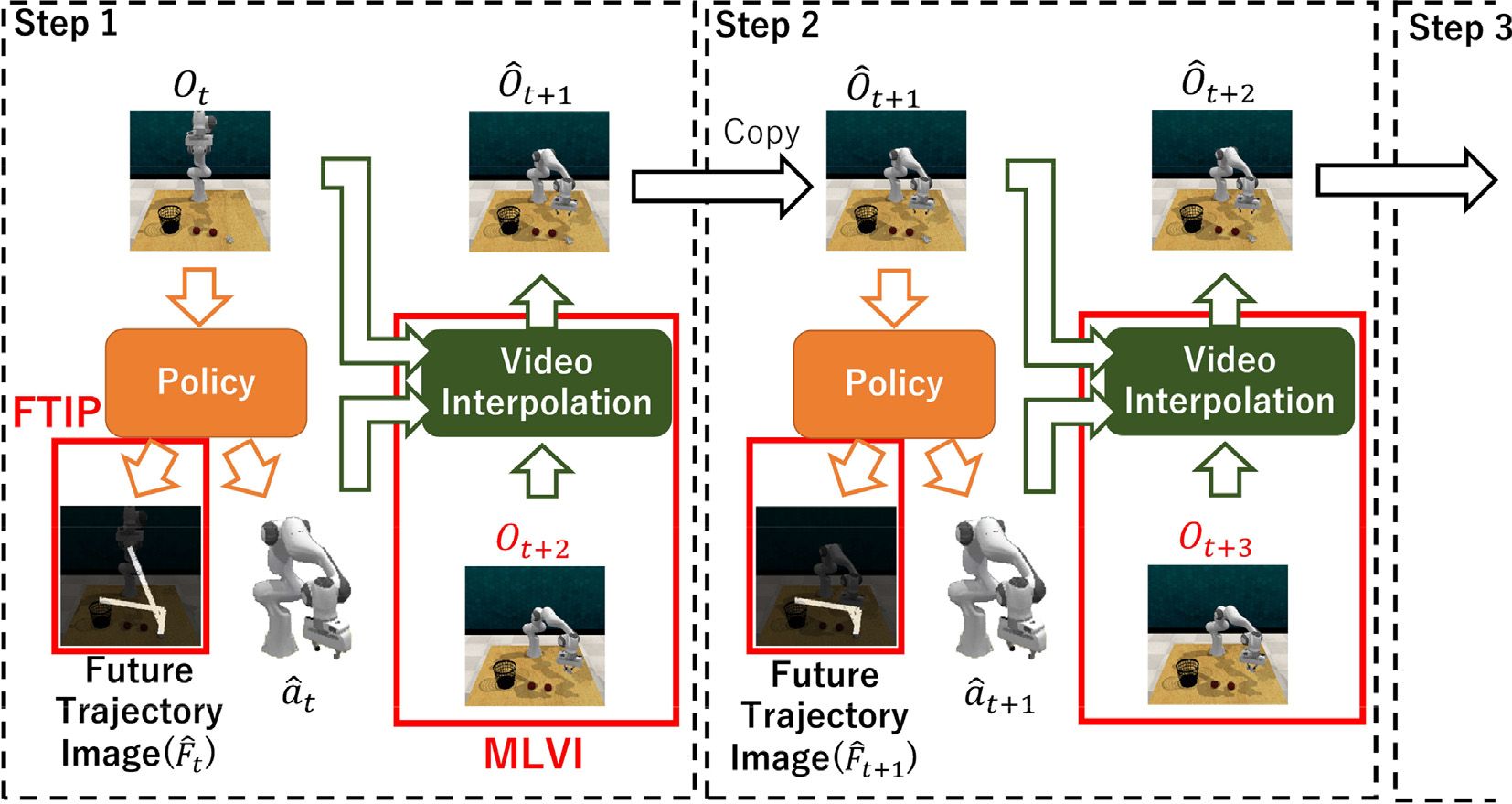
Imitation learning is the task of optimizing a policy network to imitate demonstrations. The policy sequentially predicts each time-step action based on observations. The observations are videos in this study. Offline imitation learning only uses a pre-collected demonstration dataset to train the policy and thus is applicable even in scenarios where interaction with the environment, or exploration, is impractical in the training stage. One of the problems of offline imitation learning is error accumulation. Since the prediction error is accumulated along time-steps, the distribution of future observations is gradually shifted from the pre-collected dataset. One of the solutions is utilizing a forward dynamics model that predicts the observation of the shifted distribution from past observations and actions. This forward dynamics model enables the optimization of the policy to minimize the accumulated error. However, there are still the following two problems: (1) Since predicting future observations is an extrapolation problem, it is difficult to predict observations correctly because of the uncertainty. (2) Since the policy and the forward dynamics model are used recurrently, optimizing the policy with long sequences takes a vast amount of memory. In this paper, we resolve these problems using (1) a new forward dynamics model that predicts the observation as interpolation and (2) auxiliary learning of future-trajectory images that makes a policy learn the ideal future state without recurrent learning. We demonstrate that our proposed methods reduce the accumulated error and improve the task success rate in various robot manipulation tasks in a simulator.