・非剛体群追跡,および位置・姿勢推定
観測画像を解析することにより追跡対象の数,軌跡,速度などを得ることができれば,シーンの状況,対象の行動特性,対象の意志,対象の行動予測などの情報を自動的に取得することが可能になる.さらに観測対象の姿勢まで推定することができれば,より詳細な対象に関する情報を自動的に得ることができるため,システムの応用範囲を大きく拡げることができる.また,手法の用途を広げるためには多数対象や非剛体の位置・姿勢推定にも対応できることが望ましい.
そこで本研究では,以下に示すアプローチによって任意の非剛体群の位置・姿勢推定を目指して研究を進めている.
- 非剛体の関節と仮定できる位置で非剛体を分割し,分割された各領域に対して部位モデル(ここでは、単一の形状で表現できるモデルとする)を自動生成する.
- 関節箇所での各部位モデルの角度変化を許容した部位モデル集合を統合することにより,非剛体を1つの対象モデルとして表現する.
- 非剛体の骨格線(ここでは,物体領域の中心を表す線とする)を参照して姿勢を推定する.
- 少ない外見的特徴でも対象らしさを評価でき,どの物体にも存在するような以下の特徴量を用いる.
- 骨格線情報
- 色ヒストグラム
- 面積
- 追跡時に用いる特徴量に基づいてモデルを自動生成することにより,生成されるモデルや特徴量が追跡手法における対象識別に適していることを保証する.
- 信頼できる部位モデルを基準に,その他の部位モデルの位置を定める.これにより,特徴量が少なくて位置が特定できない部位モデルも対象の各部位と正確な対応が得られる可能性が高くなる.
金魚をターゲットにした実験結果を図1([動画1]
[動画2]),人間をターゲットにした実験結果を
図2に示す.
人体や着衣による遮蔽に対して頑健な姿勢推定を行なうためには,複数カメラにより対象を多方向から撮影して得られる3次元形状(ボリュームデータ)に基づく手法が適している.
3次元形状を取り扱うことにより,その後の詳細な形状解析への展開も可能となる.
計算コストを要する3次元復元も,高速かつ安定な視体積交差法の利用により形状復元そのものは実時間実行が可能であり,それに続く姿勢推定の高速化によりオンラインシステムの実現も十分に可能となってきている.
3次元形状に基づく手法では,復元ボリュームとモデルの重なりが最大になるモデルパラメータを求めることにより姿勢推定が行われる.
しかし,従来法は「各体節は剛体として近似可能」という大きな仮定に基づいている.
そのため,観測対象の着衣が着物のようなルーズな着衣の場合,人体の運動により着衣を含む各体節の形状は大きく変形してしまうので各体節を剛体近似できず,上記手法を適用することは困難である.
また,視体積交差法のように実時間処理可能な手法では復元ボリュームには大きな誤差が含まれることも多々あるため,この復元結果を信頼して人体モデルとのマッチングを行なってしまうと推定は大きく誤ってしまう.
そこで,本稿では以下の特徴を備えた「視体積交差法により生成される時系列ボリュームデータを用いた人体・着衣の形状解析」を目的とする.
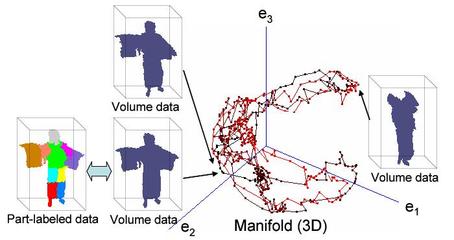
提案手法では,詳細解析により得られる対象の高精度形状の時系列変化を体節ラベル付で事前に学習し,この学習データと入力データとの比較による形状解析を行う.
また,学習データ探索の高速化のため,時系列形状は主成分分析して固有空間上の多様体として記録する図3.
その固有空間上にオンラインで計算される入力形状を投影し,学習データ中から類似データを探索することにより,各体節情報をもった高精度形状を獲得する.
この獲得形状とオンライン復元形状の比較により,目的とする各体節部位の特定および復元誤差の除去が可能となる.
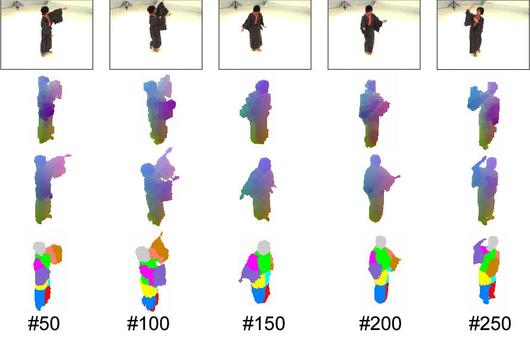
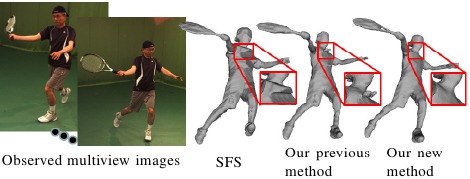
提案手法の有効性を示すため,形状変化の大きい着物を着衣とした実験を行った結果を図4([動画])に示す.
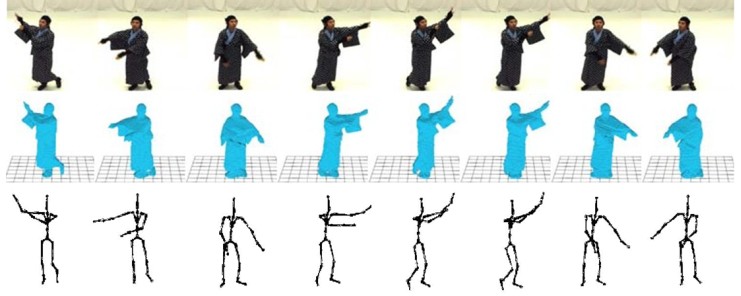
同期ビデオ群より獲得した人体の3次元形状から人体の姿勢推定を行う.この手法は1)着衣の非剛体,剛体など対象を選ばず複雑な形状変化に対応可能,2)複雑形状の復元結果に含まれる推定誤差を反映,修正した頑健な姿勢推定が可能,という特長を持つ.提案法では,オンライン復元形状を誤差修正済みの形状変化の動的モデルと比較することで復元誤差の修正を実現する.この際,視体積領域の持つ幾何学的な制約を導入することで復元誤差に頑健な形状推定が可能である.また,各時刻の形状と姿勢(関節位置および角度)を対応付けて学習し,復元形状から姿勢推定を行う.形状変化が複雑で復元誤差の現われやすい非剛体着衣を対象として実験を行い,提案手法が従来法と比べて高精度な姿勢推定ができることを確認できた(図5, [動画]).
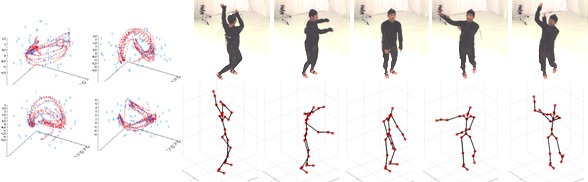
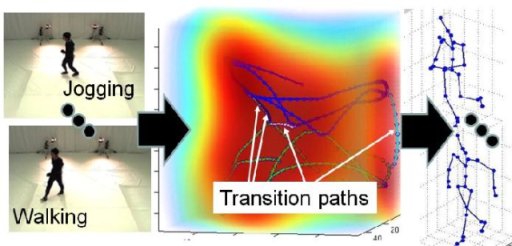
従来法では,複数の行動をモデル化する時も,学習シーケンスはすべて単一行動のモデル化の際と同様に処理されていた.このままでは,行動と行動の切り替わり(例:歩行からジョギングに移る瞬間)に姿勢推定の精度が下がってしまう.そこで,異なる行動間の切り替わりに対応する学習データを仮想的に生成することにより,なめらかな姿勢追跡を実現するためのモデルを2種類提案した.1つめは,比較的類似した行動をまとめて1つのモデルとして学習する方法,2つめは,姿勢が大きくことなる行動をそれぞれ別々にモデル化しておく手法である.それぞれの実験結果を図6,図7に示す.
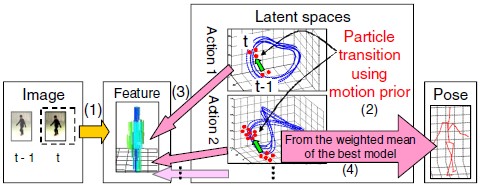
人体の動きを動作ごと(歩行,ジョギングなど)にモデル化した学習データを参照し,映像からその姿勢を追跡する手法を提案する.学習は基本的な動作毎に行うため,1)各動作モデルを適宜追加可能,2)各モデルはその動作に特化した最適化が可能となる.追跡時は,観測動作に合わせて動作モデルを自動的に切替えながら姿勢を追跡する(図13).この切替が遅れると,動作間をまたぐ人の動きに対する追従性が損なわれてしまう.提案手法では,モデル間で動作の遷移が発生する可能性のある箇所をデータの類似性に基づいて特定し,その遷移候補点間をなめらかに繋ぐ姿勢変化を仮想的に生成することにより,モデル間の即応的な遷移および遷移時の姿勢追跡精度の向上を実現する.実際の計測データとこれらの仮想的に追加したデータを学習データとして用いることにより,姿勢追跡の精度向上が可能であることを示す.
滑らかで正確な3次元表面形状を多視点画像から得るための手法を提案する.提案手法では,表面点群と法線から陰関数表現により3次元表面形状を得る手法を利用する.陰関数表現による復元表面形状の精度は,点群と法線の精度に加え,それらの間の整合性にも強く依存する.そこで,陰関数表現による表面形状復元に適するという特徴を重視して,多視点画像から点群と法線を獲得する.こうした特徴を備えた点群と法線の獲得のため,視体積交差法とステレオ視を独立に適用し,各手法の上記特徴に対する適正(例:点群の信頼性や法線の滑らかさ)を考慮しながら復元結果を統合する.実験により,提案手法が復元の精度や安定性において類似手法よりも優れていることを確認した(図8).
We propose a new simple approach to represent and manipulate a
mesh-based character animation preserving its time-varying
details. Our method first decomposes the input mesh animation into
coarse and fine deformation components. A model for the coarse
deformations is constructed by an underlying kinematic skeleton
structure and blending skinning weights. Thereafter, a non-linear
probabilistic model is used to encode the fine time-varying details of
the input animation. The user can manipulate the corresponding
skeleton-based component of the input, which can be done by any
standard animation package, and the final result is generated
including its important time-varying details. We demonstrate the
performance of our method by converting and editing several mesh
animations generated by the state-of-the-art performance capture
approaches (図10).
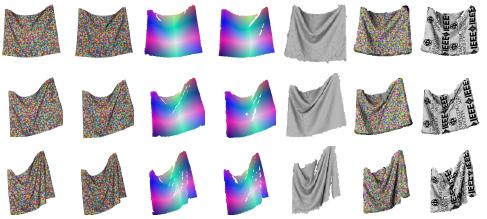
We propose a multiview method for reconstructing a folded cloth
surface on which regularly-textured color patches are printed. These
patches provide not only easy pixel-correspondence between multiviews
but also the following two new functions. 1) Error recovery: errors
in 3D surface reconstruction (e.g. errors in occlusion boundaries and
shaded regions) can be recovered based on the spatio-temporal
consistency of the patches. 2) Single-view hole filling: patches that
are visible only from a single view can be extrapolated from the
reconstructed ones based on the regularity of the patches. Using these
functions for improving 3D reconstruction also produces the patch
configuration on the reconstructed surface, showing how the cloth is
deformed from its reference shape. Experimental results demonstrate
the above improvements and the accurate patch configurations produced
by our method (図11).
複数のパンチルトカメラで人体の各部をズームアップ撮影することで,形状復元の解像度向上と誤差低減,および高解像度テクスチャ撮影を可能とするシステムを開発する.技術課題は,各瞬間においてより形状復元誤差が小さく,かつ多くの高解像度テクスチャを撮影できるようにすべてのパンチルトカメラの視線方向を決定することにある.このカメラワークのためには,対象である人体形状の動きが有用な情報となる.しかし,人体全身の形状を実時間で解析することは難しいため,撮影動作を既知とし,事前計測した対象全身の時系列形状において,各ズームアップカメラの撮影対象候補である人体パーツの配置を解析し,学習しておく.本番撮影時には,オンラインで復元された形状と学習データを比較し,類似する学習データに対応する人体パーツの配置から,オンラインの人体パーツ配置を推定する.この配置に基づき,複数の簡易な評価関数からカメラワークを高速決定する.実験では,学習データを用いた実時間カメラワークと,撮影された高解像度画像からの3次元ビデオ生成を行い,提案システムの有効性を確認した(図12).

・緩い着衣を含んだ人体の実時間姿勢・形状解析