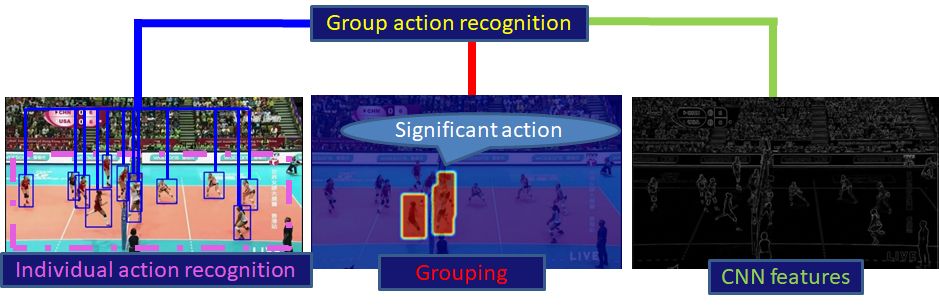
As shown in the figure above, we conduct group activity recognition using three pieces of information, Individual action recognition, grouping, and the feature amount of the entire scene. I will explain Individual action recognition and grouping playing an important role in this information.
blocking

digging

falling

moving

setting

spiking

standing

waiting

Individual acion recognition is to select from the labels of actions given which actions it is in trimmed video. It is obvious that it becomes quite useful information in group activity recognition because it is possible to identify what kind of action the player appearing in the scene is doing by recognizing Individual action. The label of Individual action recognition of this time is "blocking", "digging", "falling", "moving", "setting", "spiking" , "Standing", "waiting" in total.

This flow of Individual action recognition is indicated by the above figure. Firstly we will detect and track individual players in order to extract individual players from the whole image. With this detection, we extract the position where the player is in each frame by using SSD (Single Shot multibox Detector) method. If you only get out the position, this detection may seem good. However, although it is possible to obtain the position of a player of a frame alone, it is not known which player obtained in a certain frame corresponds to any player obtained in the next frame. It is the tracking that carries out correspondence of players between this frame. This tracking is determined by the detection box obtained in the previous frame and the IoU in the next box. Detected images of Individual action can be obtained by this detection and tracking. The aspect ratio of this image is constant in a series of frames, and the background of parts other than the detection box is blackened.
Next, we will input this obtained image independently into CNN. This network uses ResNet152. With this network, all the players obtained by detection and tracking can recognize Individual action.
Let's think what is important in group activity recognition. If you understand what the scene is doing, I think that you should understand what all the players are doing. But when we see the game, do we know exactly what every player is doing? Most people think that the scene is judging what is happening by seeing players near the ball and players who are making distinctive movements. We humans are trying to understand the scene by naturally finding players playing an important role in the scene. This grouping is motivating to realize "selection of significant players out of many players" by these human with nature in the neural network.
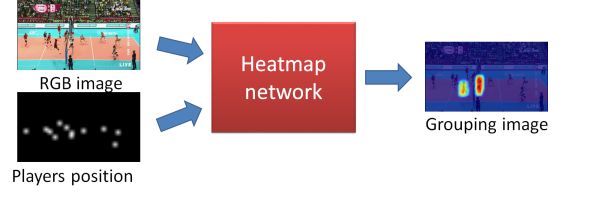
The flow of the grouping method is as shown in the above figure. Grouping is a method to obtain images in which only significant players are emphasized by heat maps (output images) from RGB images and images of player positions (input images). The player position image used for input is created using the result obtained by SSD & tracking. What we expect in this process is to select significant players taking into consideration feature and position information by giving information on RGB image and player position. In this way there are two merits of expressing significant players directly on the image.
First, by expressing directly in the image, we can obtain what kind of position, relationship, action as the players by one image. In other methods, the position relation is represented by discrete information. However, the proposed method can obtain more flexible information in the position relation.
Second, we are able to handle players who played occlusion (players are overlapped.) In other method, the relationship between players is expressed from detected results (like SSD and tracking of this research). However, it is not possible to accurately detect hidden players by occlusion with the current object detection technology. Also, in team games such as volleyball, it is often the case that the players hidden by the occlusion have an important meaning. The grouping, which is the proposed method, can also express players who are hidden by the occlusion because they are directly expressed in the image.