In this experiment, we used 27216 training videos and 13609 test videos.
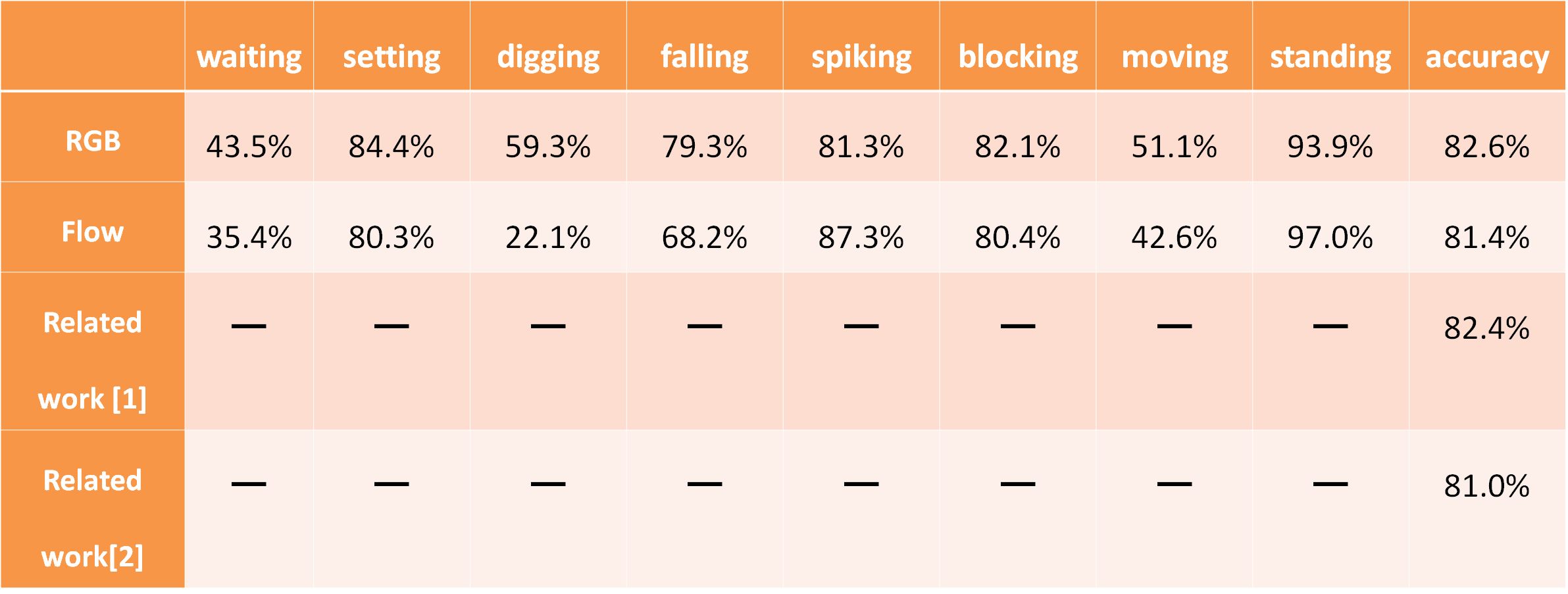
The above two results (RGB and FLOW) are the proposed methods of Individual action recognition , and the second two are the related works of Individual action recognition. "Setting", "falling", "spiking", and "blocking", which are characteristic of motion, have a good recognition rate, but there is no difference in their behavior. "Waiting", "digging", don't have a good recognition rate. "Standing" is about 75% of the dataset, so it is easy to recognize.
In this experiment, we used 1442 training images and 357 test images.
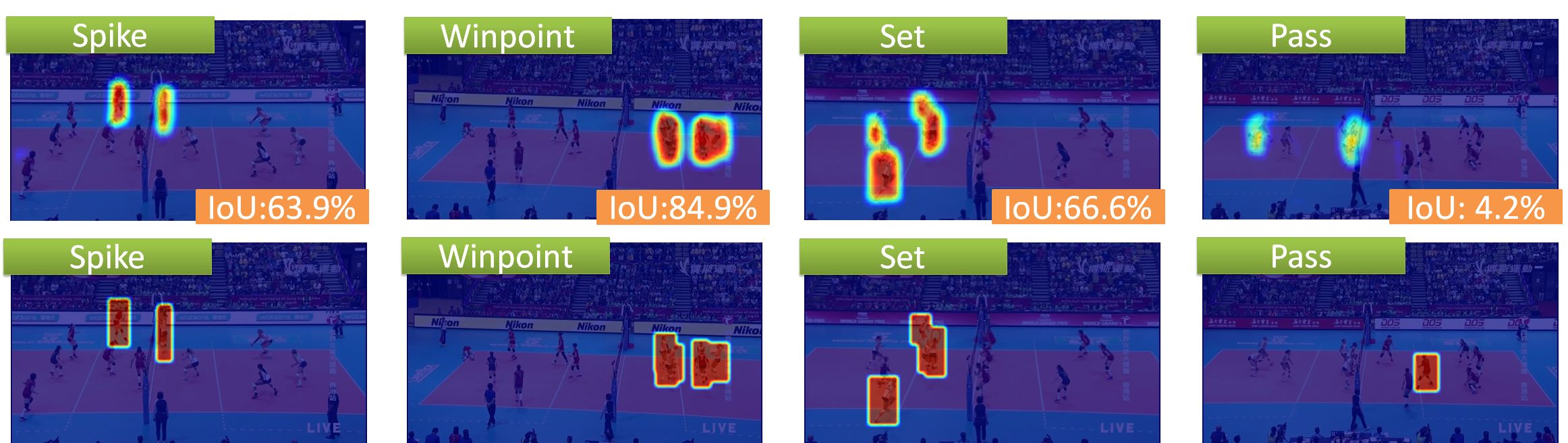
The figure above shows the results of the grouping, the upper row is the estimation result, and the lower row is GT image. GRouping is evaluated according to how much the area of the estimated heatmap overlaps the area of the GT heatmap of the lower. I will quantitatively evaluate with IoU. In the upper image, "spike", "winpoint" and "set" have relatively high IoU and "pass" has low IoU.

I also looked at the mIoU, which is the average of the IoUs for each class based on the total test dataset. Grouping is supposed to be done correctly if IoU exceeds 50%, because object detection is assumed to be correct if IoU exceeds 50%. The reason why the result of the pass is bad is that since the pass is similar to other actions, it is difficult to learn the individual action recognition and grouping.